前几天Blackhat上,有一个有意思的议题,《Reflected File Download,A New Web Attack Vector》,瞬间觉得高大上,就拿来膜拜了一下,经过膜拜发现不知道是我不能完全理解还是什么原因,总是觉得这种攻击方式略微鸡肋.我简单的把膜拜的过程记录下发出来,让各路基友帮忙看看,到底该用什么姿势去膜拜才是正确的.
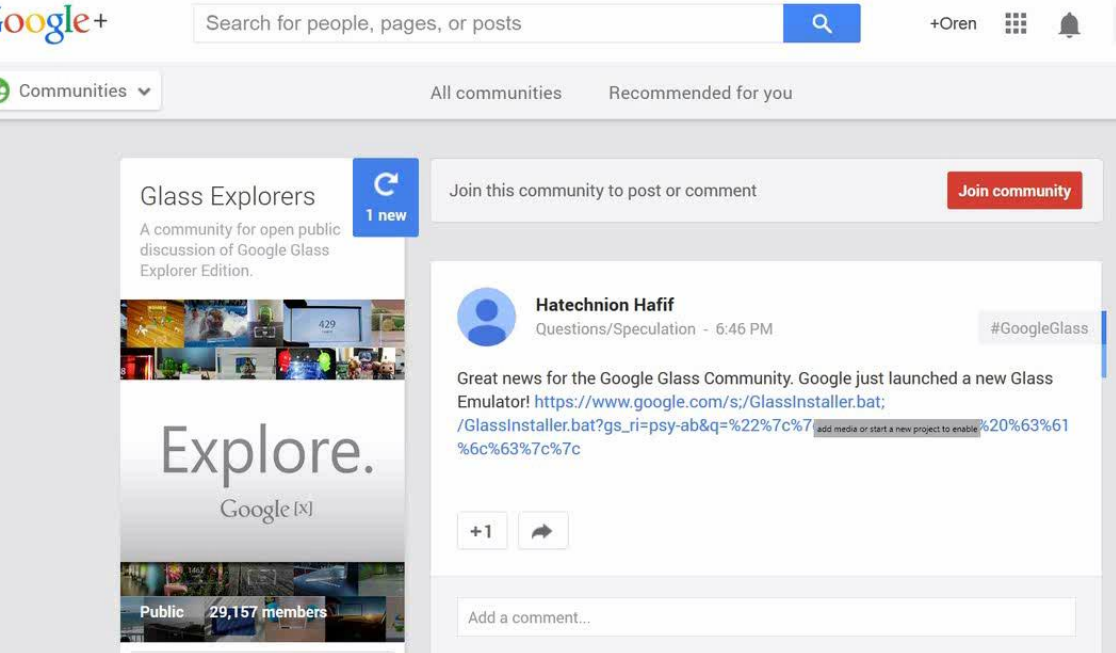
Reflected-File-Download-Attack,我觉得可以翻译成"反射型文件下载",感觉跟反射型Xss类似,在Hafif的PPT里是这样描述的: “用户点击一个来自google.com的链接,会下载一个恶意的文件,一旦用户点了这个文件,这个文件就立即运行,windows的计算器就弹出来了(PPT第17页)”“Uploadless Downloads!(P18)”
由于那个漏洞google.com修复了,这里我找了一个百度的有类似风险的链接,来膜(实)拜(验)。
首先看实验,然后在详细说原理: 如果你的浏览器是chrome,那么使用这个链接:
http://suggestion.baidu.com/su;/1.bat;?wd=&cb=calc||&sid=1440_2031_1945_1788&t=1362056239875
如果你的浏览器不是chrome,那么使用这个链接:
http://suggestion.baidu.com/su;/1.bat?wd=&cb=calc||&sid=1440_2031_1945_1788&t=1362056239875
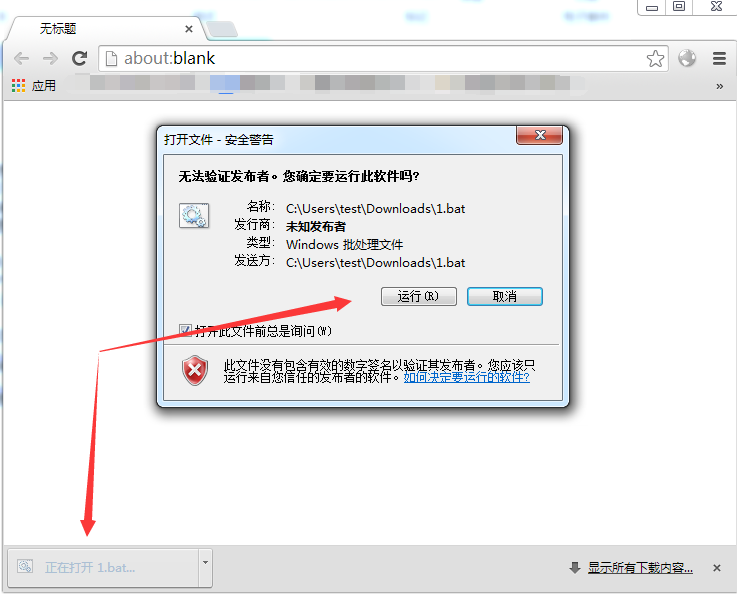
当你点击了这个链接,你的浏览器会提示下载:
细心的童鞋在url中就已经发现了,内容都写在url里了,很显然如果你运行了,就会弹出计算器:

当然,肯定会有童鞋说,你以为我是SB吗,我才不会去点他呢。。(遇到这问题我竟无言以对,确实鸡肋)
这个议题的演讲人在PPT里面有一段大概这样意思的描述:我们是如何去相信我们的下载呢?(P20)
我觉得这个漏洞的最大价值也就在于普通用户去分辨是否恶意下载是靠各种浏览器地址框的绿色证书标识,是靠HOST,注意这里说的是普!通!用!户!
在这个例子里,如果我们不对url进行任何修改,打开后会下载会一个文件,名字是su:
http://suggestion.baidu.com/su?wd=&cb=window.bdsug.sugPreRequest&sid=1466&t=1362316450913
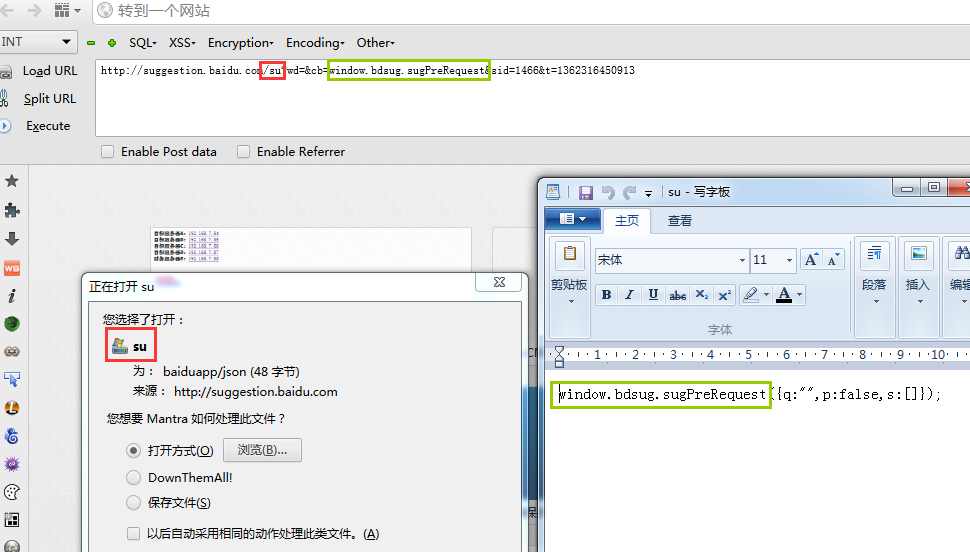
从图中我们可以看出两个对我们有用的地方:
1.红框处,下载的文件名字跟url后面跟的su一样,这里我们可以试试能不能通过修改这里使下载的文件名变成我们想要的。 2.绿框处,cb字段输入的内容在返回中出现了,这里我们可以试试能不能通过修改这里使文件的内容变成我们所需的。
通过实验,得到下面这个能够执行命令的url:
http://suggestion.baidu.com/su;/1.bat;?wd=&cb=calc||&sid=1440_2031_1945_1788&t=1362056239875
这里我们打开这个.bat:

这段字符串用被管道符隔成了两段命令,第一段是弹计算器,第二段是无效命令。 这个例子没有Hafif的PPT里的那个例子好,如果在我们能控制的输入位前面还有一些字符串,我们仍然可以使用管道符分隔开两段字符串。例如:
{"results":["q", "rfd\"|| calc|| ","I loverfd"]}
我们再来看一下数据包,如果我们想要下载一个文件,遵循正常http协议,那么他的http头中要包含 Content-Disposition字段,并且参数为attachment,这个字段还有个字段是filename,也就是说如果想要使用下载功能这个字段的标准写法是这样的:
Content-Disposition:attachment;filename:1.txt
但是google产生漏洞的这个位置并没有加filename参数。按理来说百度这个地方的安全风险也应该是这样产生的,但是在实际测试中我们发现,并不是这样的。 先看一下百度的返回包:
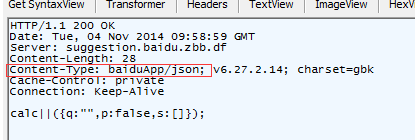
虽然没有那个强制下载的字段Content-Disposition,但是我们仍然成功下载了,这里就产生了一个问题。。。
在后面的测试中我们发现,是因为content-type字段的内容造成的,按照http协议,content-type的json返回包的正常写法是这样的:
Content-Type: application/json;
为了验证是哪里的问题,我们继续尝试:
http://weibo.com/aj/top/topnavthird?_t=1&_v=WBWidget.cssVersionCallback
这个微博地址返回的是json的数据,并没有下载行为,他的返回包是这样的:

现在我把修改返回里的content-type字段为baiduApp/jason:
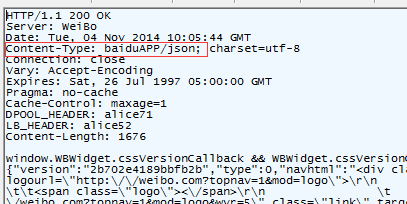
发现页面文件发生了下载行为!

经过接下来的尝试我们发现,如果content-type不符合http协议,也就是说不是标准的application/json写法,而是baiduAPP/json或者xxxx/json,甚至Fuck/json,都会使页面产生下载行为!
(我也不能完全确定是不是不符合HTTP协议,各路基友求证实)
这样这个漏洞形成的原因就很简明了,要符合几个条件:
1.在返回中能看到我们的输入并且content-type的类型不是普通类型,json或者jsonp等等。。。
2.url没有过滤或转义‘/’‘;’
3.是下载类型。使用不完整的Content-Disposition:attachment或者是不符合http协议的content-type。
原理上基本就这样了,至于利用上这的确是有一定的鸡肋,不过类似反射型XSS,如果在社交网络中使用,效果还是很不错的,例子我就不举了,这里贴个Hafif在PPT中的例子。效果好坏完全看你的忽悠能力了!!
PPT里面还有关于如何修复,这里我就不说了,感兴趣的童鞋可以去看看,附上PPT下载地址:http://dakrsn0w.sectree.cn/RFD.pdf